Computer Vision (CV) Concepts and in Azure
Source: My personal notes and comments from course series Introduction to AI in Azure, Introduction to computer vision concepts - Training | Microsoft Learn
Computer Vision (CV) Introduction
Section titled “Computer Vision (CV) Introduction”Computer Vision allows AI to see the world and understand it.
Example use cases:
- A hospital wants to detect and track surgical instruments in real-time during operations.
- A retail company needs to classify products like shoes, shirts, and electronics, in images into categories.
- A wildlife preservation organization needs to identify the animals that walk through video footage.
- A city’s transportation department needs to read and extract text from images of license plates.
- A manufacturing company wants to analyze visual patterns for defects.
CV can do location detection of objects, object detect + analyze, and optical character recognition (OCR) which is scanning text
Overview
Section titled “Overview”Computer vision capabilities categories:
- Image analysis: detect, classify, caption, and generate insights
- Spatial analysis: understand people’s presence and movements within physical areas in real time
- Facial recognition: recognize and verify human identity
- Optical character recognition (OCR): extract printed and handwritten text from images from different languages and writing styles
Images as pixel arrays
Section titled “Images as pixel arrays”Image as a data in a computer program. An image is an array of numeric pixel values.
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 255 255 255 0 0 0 0 255 255 255 0 0 0 0 255 255 255 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
The array consists of seven rows and seven columns, representing the pixel values for a 7x7 pixel image (which is known as the image's resolution). Each pixel has a value between 0 (black) and 255 (white); with values between these bounds representing shades of gray.The array of pixel values for the image is in two dimensions with rows and columns or x and y. Most digital images have multiple dimensions with 3 layers (known as channels) that represent red, green, and blue (RGB) colours.
Red: 150 150 150 150 150 150 150 150 150 150 150 150 150 150 150 150 255 255 255 150 150 150 150 255 255 255 150 150 150 150 255 255 255 150 150 150 150 150 150 150 150 150 150 150 150 150 150 150 150
Green: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 255 255 255 0 0 0 0 255 255 255 0 0 0 0 255 255 255 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Blue: 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 0 0 0 255 255 255 255 0 0 0 255 255 255 255 0 0 0 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255 255Squares of different colours can be represented when the layers are combined.
Image Processing
Section titled “Image Processing”A common way of processing tasks is to apply filters to change the pixel values of the image to change the visual. A filter is 1 or more arrays of pixel values, called filter kernels. An example 3x3 kernel is:
-1 -1 -1-1 8 -1-1 -1 -1The filter kernel can be applied to the image one columns/row at a time to transform the image.
Because the filter is convolved across the image, this kind of image manipulation is often referred to as convolutional filtering. The filter used in this example is a particular type of filter (called a laplace filter) that highlights the edges on objects in an image. There are many other kinds of filter that you can use to create blurring, sharpening, color inversion, and other effects.
Machine learning for computer vision
Section titled “Machine learning for computer vision”Using filters to apply effects to image can be used for image processing tasks like in image editors. Computer vision tasks are more likely to be extracting meaning where ML models recognize features in many images.
-
Convolutional neural networks (CNNs)
CNN is a type of deep learning architecture and uses filters to get numeric feature maps from images and input the feature values to a deep learning model for label prediction.
An example is image classification and the label prediction answers what is the subject of the image. CNN models could be used to identify kinds of fruit.
-
CNN for an Image Classification Model
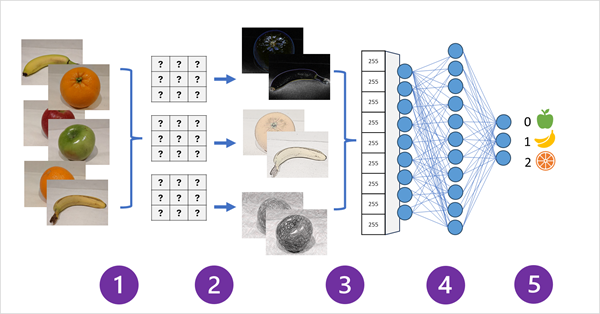
image classification model where pictures of fruit are input and predictions are made - Images with known labels are input into the network for training
- 1 or more layers of filters are used to get features from each image in the network. Filter kernels have random weights to start and create arrays of numeric values called feature maps
- Feature maps are flattened to single dimension arrays of feature values
- Feature values are input into the neural network
- Neural network’s output layer uses a softmax or similar function the output a probability values for each possible class
Model evaluation and iteration:
During training the output probabilities are compared to the actual class label - for example, an image of a banana (class 1) should have the value [0.0, 1.0, 0.0]. The difference between the predicted and actual class scores is used to calculate the loss in the model, and the weights in the fully connected neural network and the filter kernels in the feature extraction layers are modified to reduce the loss.
The training process repeats over multiple epochs until an optimal set of weights has been learned. Then, the weights are saved and the model can be used to predict labels for new images for which the label is unknown.
This explanation is a simplification. CNN architecture in reality includes multiple convolutional filter layers to reduce the size of feature maps and constrain/control feature values.
-
Vision models
Section titled “Vision models”CNN is a core of computer vision and base for more complex models. An example is object detection models combine CNN feature extraction layers with identification of regions of interest in images to find multiple classes of entities in the image.
-
Transformers
See Transformers section of these notes:
-
Multi-modal models
Multi-modal means the model can process text, language, images, and other media.
AI researchers use the transformers approach to build language models and considered it for image data resulting in multi-modal models. These multi-modal models train on captioned images with no labels.
An image encoder extracts features from images based on pixel values and combines them with text embeddings created by a language encoder. The overall model encapsulates relationships between natural language token embeddings and image features Foundation models are pre-trained general models with language encoder and image encoder that can be used to build adaptive models for specialized tasks like:
- Image classification: get image category
- Object detection: find objects in image
- Captioning: descriptions of images
- Tagging: list of relevant text tags for image
Computer Vision in Azure
Section titled “Computer Vision in Azure”Example use cases:
Manufacturing – Defect Detection: AI vision systems inspect products on assembly lines in real time. They detect surface defects, misalignment, or missing components using object detection and image segmentation, reducing waste and improving quality control.
Healthcare – Medical Imaging Analysis: Computer vision helps radiologists analyze X-rays, MRIs, and CT scans. AI models can highlight anomalies like tumours or fractures, assist in early diagnosis, and reduce human error.
Retail – Shelf Monitoring: Retailers use AI vision to monitor store shelves. Cameras detect when products are out of stock or misplaced, enabling real-time inventory updates and improving customer experience.
Transportation – Autonomous Vehicles: Self-driving cars rely on computer vision to recognize road signs, lane markings, pedestrians, and other vehicles. This enables safe navigation and decision-making in dynamic environments.
Applications of Azure AI Vision image analysis and face detection:
- Search engine optimization - using image tagging and captioning for essential improvements in search ranking.
- Content moderation - using image detection to help monitor the safety of images posted online.
- Security - facial recognition can be used in building security applications, and in operating systems for unlocking devices.
- Social media - facial recognition can be used to automatically tag known friends in photographs.
- Missing persons - using public cameras systems, facial recognition can be used to identify if a missing person is in the image frame.
- Identity validation - useful at ports of entry kiosks where a person holds a special entry permit.
- Museum archive management - using optical character recognition to preserve information from paper documents.
Vision Studio (Can try free)
Section titled “Vision Studio (Can try free)”Services are: Azure AI Vision including Vision Studio, Azure Face which is restricted by responsible AI use
Can read text, detect object, person, tag things, but no face detection. Face can detect face landmarks like eyebrows.
Azure CV supports lower level OCR and video
Azure AI services for computer vision
Section titled “Azure AI services for computer vision”- Azure AI Vision Image Analysis service: Detects common objects in images, tags features, create captions, and optical character recognition (OCR).
- Azure AI Face service: Detects, recognizes, and analyzes human faces in images. Models for facial analysis that extend beyond image analysis.
Some solutions have multiple capabilities like Azure AI Video Indexer which uses Azure AI Face, Translator, Image Analysis and Speech.
Azure AI Vision Image Analysis capabilities
Section titled “Azure AI Vision Image Analysis capabilities”These abilities are available without customization:
- Captioning images: a description of the image
- Detecting common objects: lists of object and confidence score
- Tagging visual features: objects, activities like person actions and movements, concepts in image
- OCR: detect text in image and extract it
Training a custom model is possible for image classification and object detection by building from foundation models. For example, training a model to detect type of fruit.

Custom model creation is described at Create a custom Image Analysis model - Azure AI services | Microsoft Learn.
Azure AI Vision’s Face service capabilities
Section titled “Azure AI Vision’s Face service capabilities”Use cases are checking user identity, liveness, detection, touchless access control and face redaction (masking).
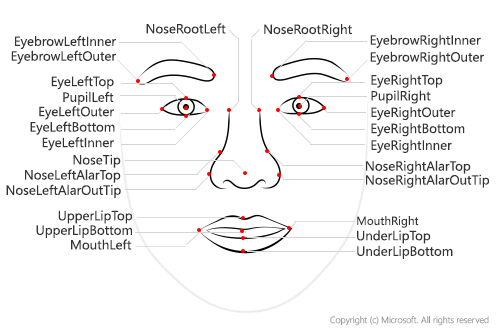
Face detection will identify locations of human faces with bounding box coordinates.
- Face detection - locate faces in image
- Face attribute analysis: analyze features of faces (head position, occlusion)
-
Facial recognition
Facial analysis allows identifying specific people from their facial features which is known as facial recognition.
-
Azure AI Face service capabilities
Azure AI Face can locate human faces as well as:
- Accessories: indicates whether the given face has accessories. This attribute returns possible accessories including hats, glasses, and mask, with confidence score between zero and one for each accessory.
- Blur: how blurred the face is, which can be an indication of how likely the face is to be the main focus of the image.
- Exposure: such as whether the image is underexposed or over exposed. This applies to the face in the image and not the overall image exposure.
- Glasses: whether or not the person is wearing glasses.
- Head pose: the face’s orientation in a 3D space.
- Mask: indicates whether the face is wearing a mask.
- Noise: refers to visual noise in the image. If you have taken a photo with a high ISO setting for darker settings, you would notice this noise in the image. The image looks grainy or full of tiny dots that make the image less clear.
- Occlusion: determines if there might be objects blocking the face in the image.
- Quality For Recognition: a rating of high, medium, or low that reflects if the image is of sufficient quality to attempt face recognition on.
-
Responsible AI use
Azure AI Face and Azure AI Vision have a Limited Access policy which restricts use of face verification, identification, and liveness on customer request to Microsoft.
-
Get started in Azure AI Foundry portal
Azure AI vision can be accessed with the Azure AI Foundry portal or SDK or REST API.
Azure resources are required:
- Azure AI Vision: good if you don’t intend to use any other Azure AI services or if tracking and costs for your Azure AI Vision resource separately.
- Azure AI services: general resource that includes Azure AI Vision along with many other Azure AI services; good if you plan to use multiple AI services
The Azure AI Foundry portal has a user interface to hubs and projects. Hubs manage resources while projects hold datasets, models, and other resources for solutions.