Microsoft Azure AI Fundamentals: Generative AI
Source: My personal notes and comments from Introduction to generative AI concepts - Training | Microsoft Learn course, Retrieved 2025-08-03 and comments from course series Introduction to AI in Azure.
Use cases for generative AI can be:
- Create new content like natural language, text, image, video
- Assistants and custom ones to build on for complex applications like use of agents
- Analyze and use data
What is Generative AI?
Section titled “What is Generative AI?”- Generative AI is artificial intelligence where models are trained to generate new original content from natural language input
- Learning will show:
- Large language models (LLM) support generative AI
- About Azure OpenAI service
- Application such as copilots and use cases
- Prompt and response tuning
- Ethical AI
- Takes natural language input from a person and returns responses like language, images, code, and media.
Large Language Models (LLM) and How they work
Section titled “Large Language Models (LLM) and How they work”A LLM is specialized type of machine learning model to do natural language processing (NLP) tasks.
Data, processors and time are used to train LLMs which results in billions-trillions of parameters. More parameters means more ability of the LLM.
Tokens and Tokenization
Section titled “Tokens and Tokenization”Tokenization is to put training text in tokens to identify unique text values, could be words, partial words, and works and punctuation. With tokens, statistics can be used with computers to find patterns and apply rules.
For example:
I (1)heard (2)a (3)dog (4)bark (5)loudly (6)at (7)("a" is already tokenized as 3)cat (8)The sentence can now be represented with the tokens: [1 2 3 4 5 6 7 3 8]. Similarly, the sentence "I heard a cat" could be represented as [1 2 3 8].
As you continue to train the model, each new token in the training text is added to the vocabulary with appropriate token IDs:
meow (9)skateboard (10)and so on...Word Embeddings
Section titled “Word Embeddings”The application of deep learning techniques to NLP is word embeddings which helps set the semantic relationship between words.
They are created during self-supervised learning. During training, model finds occurrence of patterns of words in sentences and represents them as vectors (coordinates in a multidimensional space).
A vocabulary is developed that holds semantic relationships between the tokens. The vocabulary has contextual vectors for the relationships known as embeddings.
The semantic relationship is the distance between vectors
- For example,
bikeandcarare used in same patterns of words and are used like driving, buying, or repairing them. As a result, the model will put the bike and car words close in vector space. See Vector Database - Vector Database for more on vectors and a simple example - The training can have issues like:
- Words of
loveandhatemay seem related, despite being different - Single words like
bank(place, verb, business, item) can be different meanings and could be related to many words and will be semantically different depending on usage
- Words of
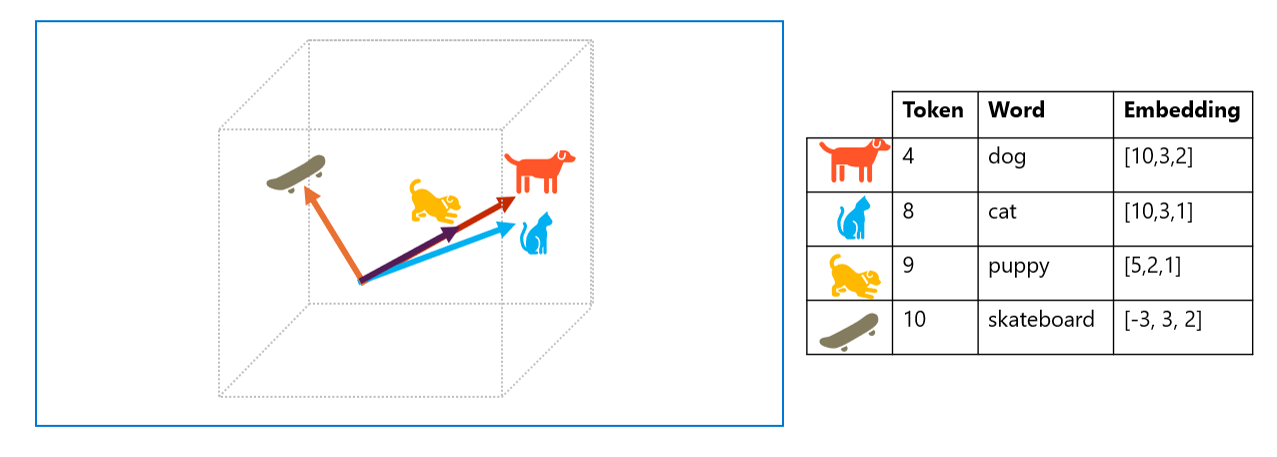
A technique called cosine similarity is used to determine if two vectors have similar directions (regardless of distance), and therefore are semantically linked words.
Example from the figure caption:
- Embedding vectors for “dog” and “puppy” describe a path along an almost identical direction, which is also
- Dog and puppy are on similar to direction to “cat”
- The embedding vector for “skateboard” is in a different direction.
Architectural developments - Need for Context
Section titled “Architectural developments - Need for Context”As a explained in word embedding, context is important in the use of the word, but currently not stored due to complexity and cost.
Recurrent Neural Networks (RNNs) can help with context since words differ in meaning depending on their context and surrounding words.
RNNs use sequential steps to take an input and a hidden state and each step makes an output and can be used as input to the next step. For example, an NLP task is the predict the value of the last word in: Vincent Van Gogh was a painter known for [MASK]. The network’s memory is given information about Vincent and through multiple steps can process words in the sentence together to predict the [MASK] token. For example, Vincent Van Gogh was a painter known for Starry Night .
Challenges with RNNs
Section titled “Challenges with RNNs”RNN limitations:
- Hidden state is limited size
- Some words are more relevant than others in the prediction, but RNN does not know that and irrelevant information is in the hidden state and considered equally in predicting output
How transformers advance language models
Section titled “How transformers advance language models”Simplified Transformer architecture showing encoder processing input sequence and capturing context and using multi-head attention to create representation of the text. The decoder generating the output sequence by attending to the encoder’s representation and using mult-head attention on the encoded input. Positional encoding encodes text into vectors.
<generation> Starry Night and Sunflowers ^ | ---------------------------------- --------------------------------->| Decoder: Multi-head attention | | | ^ |Encoder: Multi-head attention | | | ^ | | | | | Decoder: Multi-head attention | | ---------------------------------- | ^ | |Positional encoding Positional encoding ^ ^ | | Vincent was a painter known for Vincent was a painter Starry Night and Sunflowers known for <blank>Positional encoding is the sum of word embedding vectors and positional vectors, so the encoded text includes both the meaning and position of a word in a sentence. To indicate position of a word in a sentence, an index from 0 to n can be used. For long sequences, index values will grow.
Example of indexing:
| Token | Index value |
|---|---|
| The | 0 |
| work | 1 |
| of | 2 |
| William | 3 |
| Shakespeare | 4 |
| inspired | 5 |
| many | 6 |
| movies | 7 |
About Attention
Section titled “About Attention”Transformers use of attention instead of recurrence to determine context and relationships in words. Transformers provide an alternative to RNNs. RNNs are compute intensive since they process words sequentially, Transformers don’t process words sequentially and instead process each word independently in parallel by using attention.
Attention (also referred to as self-attention or intra-attention) is a way to map new information to learned information in order to understand what the new information means.
Transformers use an attention function where a new positional encoded word is represented as a query. The output of an encoded word is a key with an associated value.
-
Example with query, keys and values
Encoding “Vincent van Gogh is a painter, known for his stunning and emotionally expressive artworks”.
When encoding the query “Vincent van Gogh”, the output may be “Vincent van Gogh” as the key with “painter” as the associated value. The architecture stores keys and values in a table, which it can then use for future decoding:
Example encoded queries:
Keys Values Vincent Van Gogh Painter William Shakespeare Playwright Charles Dickens Writer With a new query like “Shakespeare’s work has influenced many movies, mostly thanks to his work as a”, the model can complete the sentence by taking “Shakespeare” as the query and finding it in the table of keys and values with “Shakespeare” query closest “William Shakespeare” the key and associated value “playwright”.
-
Attention Function and use of Query, Keys and Values
For the attention function, the query, keys and values are all encoded to vectors. The attention function then computes the scaled dot-product between the query vector and the keys vectors. The dot-product calculates the angle between vectors representing tokens, with the product being larger when the vectors are more aligned.
The softmax function is used in the attention function. The softmax function is applied over the scaled dot-product of the vectors to create a probability distribution with possible outcomes. In other words, the softmax function’s output includes which keys are closest to the query. The key with the highest probability is then selected, and the associated value is the output of the attention function.
The Transformer architecture uses multi-head attention where tokens are processed by the attention function several times in parallel. So, a word or sentence can be processed multiple times, in various ways, to extract different kinds of information from the sentence.
The Transformer architecture allows more efficient training of models. Instead of processing each token in a sentence or sequence, attention allows a model to process tokens in parallel in various ways.
Differences in language models
Section titled “Differences in language models”Users can chose from existing models that are open source and public or proprietary.
-
Large Language Models (LLM) vs Small Language Models (SLM)
Feature LLM (Large) SLM (Small) Training Data General Focused training Parameters Billions or more Fewer Specialization General, variety of conversations More specialized Speed and Deployment Slower, difficult for local use Fast Training and Fine tuning Long, Expensive Faster to fine-tune Model Examples
LLM:
- GPT-4, Generative Pre-trained Transformer (GPT)
- Mistral 7B
- Llama 3
SLM:
- Phi-3
- HuggingFace GPT Neo
- Orca 2
More examples of models and use at AI Models - AI Models
Models will have different context sizes, which is how much input they can take in prompts and output windows. For example, GPT 4 Turbo has 128k context window and 4k output.
Improve Prompt Results
Section titled “Improve Prompt Results”Responses from generative AI assistant depends on the model and prompts that users provides.
More useful completions comes from specific and clear prompts
Prompt Creation and Considerations
Section titled “Prompt Creation and Considerations”Go through a process with Generative AI by letting the AI know:
- Goal
- Context
- Information sources to use
- Expectation on what you want
- Iterate on the previous prompt
Example: summarize the key considerations for using AI (1) described in this document (2) for a corporate executive (3). For the summary as no more than six bullet points with professional tone (4).
For context (2), optional examples can be used with these methods/instructions:
- Zero shot - provide examples of what you want
- One shot - provide one example of what you want
- Few shot - provide a couple examples of what you want
Information sources (3) provide grounding for the model like documents, emails.
Prompts can be added with:
- A system message that sets conditions and constraints like “You’re a helpful assistant that responds in a cheerful, friendly manner.”
- Previous conversation history for the session, including past prompts and responses. The history enables you to refine the response repeatedly while maintaining the context of the conversation.
- The current prompt – potentially optimized by the agent to reword it appropriately for the model or to add more grounding data to scope the response.
Prompt engineering describes the process of prompt improvement and is applicable to developers of application and consumers who want to improve the quality of responses from generative AI.
Responsible Generative AI
Section titled “Responsible Generative AI”Identify possible harms → Measure harms → Mitigate harms → Operate with minimal harm like putting warning messages
Example risks are false outputs, possible unethical use
For Responsible AI frameworks, see - Ethics in the Age of Generative AI - Ethics in the Age of Generative AI - Generative AI and Ethics - the Urgency of Now
-
Principles for responsible AI at Microsoft
- Fairness - treat all people fairly. Example: models make predictions without incorporating bias
- Reliability and safety - Example: an autonomous vehicle or patient diagnoses must be safe to use related to human life
- Privacy and security - training data may have personal details and must be kept private, even after model deployment, sensitive data must be protected
- Inclusiveness - AI must empower everyone and benefit all parts of society, regardless of physical ability, gender, sexual orientation, ethnicity, or other factors. Example: have a diverse group of people test applications
- Transparency - systems are understandable and users know the purpose of the system, how it works, and what limitations may be expected. Example: a system communicates to users about its accuracy, training data, and features that affect predictions. When personal data like faces are use in a system, the system makes clear how the personal data is handled, retained, and accessed.
- Accountability - although many AI systems seem to operate autonomously, it is the responsibility of the developers who trained and validated the models they use, and defined the logic that bases decisions on model predictions to ensure that the system meets requirements. Example: solutions use a framework of governance and principles to meet responsible and legal standards that are defined.
Details at Empowering responsible AI practices | Microsoft AI
Generative AI in Azure
Section titled “Generative AI in Azure”Example use cases for Generative AI from Microsoft
Section titled “Example use cases for Generative AI from Microsoft”Marketing Content Creation: Companies use Microsoft Copilot’s generative AI to automatically write product descriptions, blog posts, and social media content—saving time and ensuring brand consistency across platforms.
Customer Support: Businesses deploy AI-powered virtual agents that can understand and respond to customer inquiries in natural language, offering 24/7 support and reducing the load on human agents.
Code Generation: Developers use tools like GitHub Copilot to generate code snippets, suggest functions, and even write entire modules based on natural language prompts, speeding up software development.
Image and Video Generation: Designers and content creators use the latest models in Azure AI Foundry’s model catalog to generate visuals for campaigns, storyboards, or concept art—often from just a text description.
Personalized Learning and Tutoring: Educational platforms use generative AI to create custom quizzes, explanations, and study guides tailored to a student’s learning style and progress.
Generative AI applications
Section titled “Generative AI applications”User interface <– user input and app output –> Application logic <– read/write data –> data storage
For AI applications, the application logic part is powered by AI models
AI capabilities:
- Assistants - chat based to help users find information and do tasks
- Agents - can execute tasks like filing tax and managing shipping.
Agents can respond to user input or assess things autonomously and
take action. Actions can be series of tasks like show meeting details
and book a vehicle for it. Agents have:
- Language model for reasoning and understanding
- Instructions defining the agent’s goal, behaviour, and constraints
- Tools that enable the agent like APIs
Solutions can combine these capabilities and others like other AI components to work together which is known as orchestration.
-
Orchestrator, Generative AI as a Service
Microsoft Copilot is an example of a generative AI solution and orchestrator that calls generative AI models, gets data from sources like web or grounding data, and other executes other resources to complete user requests. It is multi-modal can both take media as input and also make media output.
For example, Copilot can call GPT for NLP and generative text content and DALL-E for image generation.
-
Framework for understanding generative AI applications
Generative AI applications may be categorized like:
- Ready-to-use: They do not require any programming and can be used by providing user input
- Extendable: They can be ready to use and extended using your data. Customizations give better support to the specific business processes or tasks. Microsoft Copilot is an example of ready-to-use and extendable.
- Applications you build from the foundation: Build your own assistants and assistants with agentic capabilities starting from a language model.
Tools to develop generative AI
Section titled “Tools to develop generative AI”Microsoft Azure AI Foundry is a platform for AI operations, model builders, and application development. It is a platform as a service (PaaS) and allows customization of language models and deployment for use with apps and services.
The Azure AI Foundry Portal is a user interface for building, customization and management AI applications and agents and has these components:
- Azure AI Foundry model catalog: for generative AI model selection and use
- Playgrounds: Ready-to-use environments for testing ideas, trying out models, and exploring services
- Azure AI services: build, test, see demos, and deploy Azure AI services
- Solutions: build agents and customize models
- Observability: monitor usage and performance of models
Microsoft’s Copilot Studio is another generative AI development tool which works well for low-code development for technical business users or developers to create conversational AI experiences. The resulting agent is live as a SaaS (software as a service) solution hosted in your Microsoft 365 environment.
Azure AI Foundry’s model catalog
Section titled “Azure AI Foundry’s model catalog”Azure OpenAI in Foundry models are foundation models. Models in the catalog can be deployed without training to endpoints for use and models can be customized.
Testing models in the playground and use model leaderboards helps determine models based on performance, quality, and cost.
Azure AI Foundry Capabilities and Demonstration
Section titled “Azure AI Foundry Capabilities and Demonstration”The portal provides hubs and projects. Projects live in hubs. Access to Azure AI services, Speech, Language, Vision, and Found Content Safety are available.
Lives in Resource Group (RG), can manage models. Select from many models depending on need, license, provider.
AI App design: User Interface - App Logic (AI Powered) - Storage
AI Hub sets up Connections, Compute, Security, Governance for AI Projects. AI Projects (subset of AI Hub) are where you deploy, test, build, evaluate models. AI Hub is affected by organization policies and can govern projects.
You can see model details, deploy, and use the chat playground for testing. Models can be configured.
-
Customizing Models
Ways to customize models:
-
Using grounding data
Goal: anchor model’s responses to data sources, enhancing trust and relevance
It ensures the system’s outputs are aligned with factual, contextual, or reliable data sources. Grounding might involve linking the model to a database, using search engines to retrieve real-time information, or incorporating domain-specific knowledge bases.
-
Retrieval-Augmented Generation (RAG)
See Retrieval Augmented Generation (RAG) - Retrieval Augmented Generation (RAG)
RAG allows grounding in existing data sources like documents.
-
Fine-tuning
Takes an existing mode and further training on smaller task specific data. It will specialize the model for the task and domain knowledge, improve model accuracy and relevance.
-
Managing security and governance controls
Security and governance controls manage access, authentication, and data and prevent unauthorized and incorrect access of information.
-
-
Observability
Ways to evaluate and monitor generative AI:
- Performance and quality evaluators: assess the accuracy, groundedness, and relevance of generated content.
- Risk and safety evaluators: assess potential risks associated with AI-generated content to safeguard against content risks. This includes evaluating an AI system’s predisposition towards generating harmful or inappropriate content.
- Custom evaluators: industry-specific metrics to meet specific needs and goals.
Some evaluators include:
- Groundedness: measures how consistent the response is with respect to the retrieved context.
- Relevance: measures how relevant the response is with respect to the query.
- Fluency: measures natural language quality and readability.
- Coherence: measures logical consistency and flow of responses.
- Content safety: comprehensive assessment of various safety concerns.
See Also
Section titled “See Also”- Vector Database - Vector Database
- Local AI with Retrieval Augmented Generation (RAG) using Open WebUI and Ollama - Local AI with Retrieval Augmented Generation (RAG) using Open WebUI and Ollama
- Retrieval Augmented Generation (RAG) - Retrieval Augmented Generation (RAG)
- Introduction to AI in Microsoft Azure AI-900 - Introduction to AI in Microsoft Azure AI-900