AI Information Extraction Concepts and in Azure
Source: My personal notes and comments from course series Introduction to AI in Azure, Introduction to AI-powered information extraction concepts - Training | Microsoft Learn, Get started with AI-powered information extraction in Azure - Training | Microsoft Learn
AI Information Extraction Concepts Introduction
Section titled “AI Information Extraction Concepts Introduction”Extraction helps with identifying and using content like documents, video, audio, images, and text. Uses may be to gain insights, search structured (consistent format) and unstructured (no set format) content.
Example use cases:
- A manufacturer has images of each of its products. The images need to be analyzed for defects and anomalies.
- A business works with a high volume of invoices, contracts, and reports with charts. Key data and summaries from the documents need to be extracted and logged.
- Many hours of customer calls are recorded for quality purposes. The audio needs to be transcribed, summarized, and analyzed for sentiment.
- A streaming catalog contains a large volume of video. Important moments in each video need to be tagged with metadata based on their content.
- A company needs to process employee expense claims, and has to extract expense descriptions and amounts from scanned receipts.
- A customer service agency wants to analyze recorded support calls to identify common problems and resolutions.
- A historical society needs to extract and store data from census records in scanned historical documents.
- A tourist organization wants to analyze video footage and images taken at popular sites to help estimate visitor volumes and improve capacity planning for tours.
- A finance department in a large corporation wants to automate accounts-payable processing by routing invoices received centrally to the appropriate departments for payment.
- A marketing organization wants to analyze a large volume of digital images and documents, extracting and indexing the extracted data so it can be easily searched.
- In context of learning and personal use, a student wants to extract key concepts and terms from their class notes and classroom documents. To help the student prepare for an exam, extracted class and note data will be processed by generative AI and the student to create flash cards for the student to use and search on. This use case matches generative AI and multi-modal analysis of structured data.
AI information extraction means getting meaning from content.
Overview - Information Extraction Process
Section titled “Overview - Information Extraction Process”Information extraction processes follow steps:
- Source Identification: Determine where the information resides and if it needs to be digitized
- Extraction: Use techniques based on machine learning to understand and extract data from digitized content
- Transformation & Structuring: Extracted data transformed into structured formats like JSON or tables.
- Storage & Integration: The processed data is stored in databases, data lakes, or analytics platforms for use
This module looks at extraction from images, forms, different modalities, and for mining knowledge.
Extraction of data from images
Section titled “Extraction of data from images”Vision models can process large amounts of images, transform images to numerical information and making predictions on image content.
OCR allows text recognition in images and uses ML models that recognize shapes as letters, numbers, punctuation, and text elements.

Extraction of data from forms
Section titled “Extraction of data from forms”Forms and data filled on them have semantic meaning where words and/or symbols have meaning in the context.
Document Intelligence
Section titled “Document Intelligence”Document Intelligence includes Information extraction, source identification, OCR like forms and handwriting, and scan, store, and process information.
Forms extraction gets data with semantic mean: field name, description, value.
For example, a receipt can have the name, address, and contact information of the merchant and totals and costs of things purchased. The field information can be represented as coordinates and ML models can interpret data in a document or form by recognizing patterns in bounding box coordinate locations. Results of extraction are associated with confidence levels for field and data values between 0 and 1, indicating accuracy of the extraction.
Multi-modal data extraction
Section titled “Multi-modal data extraction”Multi modal means using multiple services to extract information like from documents to audio/video.
For example, get content using a service, then another service to extract field information.
Orchestration of extraction techniques could include:
- Computer Vision to find information, text, entities in images
- NLP to find entities, phrases
- Speech recognition to take spoken words to data
- Generative AI to add to the data extraction so users can identify their own fields and descriptions, especially with unstructured content
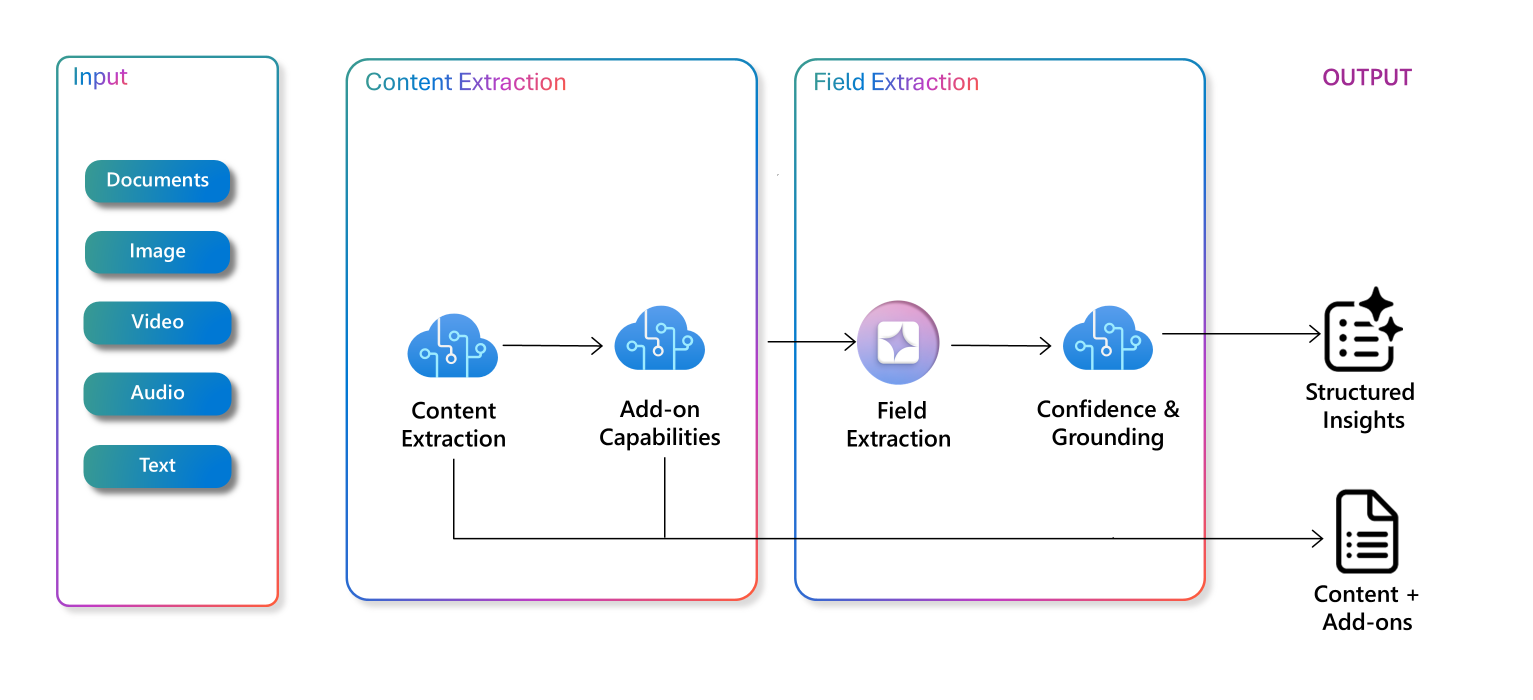
Data extraction for knowledge mining
Section titled “Data extraction for knowledge mining”Knowledge mining is automating information extraction from large amounts of unstructured data. A foundation is search and getting relevant information from data in response to a user’s query.
AI information extracted improves on search and uses these steps:
- Document cracking: opening document formats like PDFs to extract contents as ASCII text for analysis and indexing
- AI enrichment: Contents are processed by AI to add more content like captions to images, evaluating sentiment, and summaries
- Knowledge store: AI enriched content is sent to a store to persist it and for analysis or use in further processing.
Resulting data is serialized as JSON data and JSON is used to create a search index. The search index is used for queries. The search index’s structure known as a schema is like a table. The schema has fields, field data types like string, field attributes. The fields store text that can be searched and attributes help with filtering and sorting.
Example of a search index schema
{ "name": "index", "fields": [ { "name": "content", "type": "Edm.String", "analyzer": "standard.lucene", "fields": [] }, { "name": "keyphrases", "type": "Collection(Edm.String)", "analyzer": "standard.lucene", "fields": [] }, { "name": "imageTags", "type": "Collection(Edm.String)", "analyzer": "standard.lucene", "fields": [] } ]}A result in a search solution usually have these elements:
| Component | Function |
|---|---|
| API Layer | Accepts user queries and routes to search engine |
| Query Processor | Parses and interprets the query |
| Search Strategies | Determines how to search like keyword, semantic, vector, or hybrid |
| Execution Engine | Run query across search index |
| Result Aggregator | Combines results from multiple sources into a list |
| Ranking Engine | Sorts results based on relevance, freshness, popularity, or signals |
| Response Formatter | Formats results for display in the user interface |
AI Information Extraction in Azure
Section titled “AI Information Extraction in Azure”Azure AI provides these services related to extraction and analysis of information:
- Azure AI Vision Image Analysis: extract insights from images, including the detection and identification of common objects in images, captions and tagging for images, and text extraction
- Azure AI Content Understanding: generative AI-based multi-modal analysis service that can extract insights from structured documents, images, audio, and video.
- Azure AI Document Intelligence: extract fields and values from digital (or digitized) forms, such as invoices, receipts, purchase orders, and others. Parts were formerly called Forms Recognizer.
- Azure AI Search: AI-assisted indexing where pipeline of AI skills are used to extract and index information from structured and unstructured content.
Capabilities where one or more of these services are used:
- Data capture: Intelligently scanning images to capture and store data values. For example, using a cellphone camera to extract contact information from a business card.
- Business process automation: Reading data from forms and using it to trigger workflows. For example, extracting cost center and billing information from invoices and routing them to the appropriate accounts-payable department for processing.
- Meeting summarization and analysis: Analyzing and summarizing key points from recorded phone conversations or video conference calls. For example, automating note-taking and action assignments for a team meeting.
- Digital asset management (DAM): Managing digital assets like images or videos by automatically tagging and indexing them. For example, to create a searchable library of stock photographs.
- Knowledge Mining: Extracting key information from structured and unstructured data to be used for further analysis and reporting. For example, compiling census data from scanned records to populate a database.
Extract information with Azure AI Vision
Section titled “Extract information with Azure AI Vision”Azure AI Vision can be applied to images, photographs, small scanned documents like business cards and menus.
-
Automated caption and tag generation
Azure AI Vision Image Analysis allows:
- Creating a caption describing the image
- Set of suggested dense captions for objects in image
- Collection of tags for categorizing the image

man walking a dog on the street With the image above, the service generates:
Caption: A man walking a dog on a leash
Dense captions:
- A man walking a dog on a leash
- A man walking on the street
- A yellow car on the street
- A yellow car on the street
- A green telephone booth with a green sign
Tags:
- outdoor
- land vehicle
- vehicle
- building
- road
- street
- wheel
- taxi
- person
- clothing
- car
- dog
- yellow
- walking
- city
-
Object detection
Detect common objects and people in images and provide their locations as bounding box coordinates
-
Optical character recognition (OCR)
OCR works on printed or handwritten the gets the location and contents of text and individual words. For example, OCR can get text on a menu and then use translation.
Extract multimodal information with Azure AI Content Understanding
Section titled “Extract multimodal information with Azure AI Content Understanding”Using computer vision and OCR, document intelligence with generative AI can do text, image, audio, and video extraction.
-
Analyzing forms and documents
Azure AI Content Understanding’s text extraction uses OCR and includes schema based extraction of fields and values. For example, an invoice schema can be set up and the service will identify corresponding fields even if the input has no labels or different labels.

an invoice with field values identified according to an invoice schema for the organization For the detected fields, values are extracted.
-
Analyzing audio
When provided audio fields, the Azure AI Content Understanding service can give transcriptions, summaries and insights.
For example, a schema of insights can be set up for voice mails to include caller, message summary, actions, callback number, and other contact information.
-
Analyzing images and video
Azure AI Content Understanding can analyze imags and video to extract information based on a custom schema. For example, analysis of images of a video conference can extract attendance and location. Analyzing video with a schema could include attendance counts at various times, who spoke and what they said, discussion notes, and a list of actions.
Extract information from forms with Azure AI Document Intelligence
Section titled “Extract information from forms with Azure AI Document Intelligence”Can be accessed using Azure Document Intelligence Studio. Select a prebuilt model and purpose if applicable.
Azure AI Document Intelligence can do document and form processing using a library of prebuilt models like recognizing simple receipts to complex tax forms.
For example, a financial loan company can receive many mortgage applications through a form. Using an Azure AI Document Intelligence prebuilt model, a solution to locate and extract fields on the form can be created.
-
Creating custom models
Custom models are training by using labelled examples of the documents to be analyzed. The labelling involves using OCR to define the layout of the document and identifying fields to extract.
Create a knowledge mining solution with Azure AI Search
Section titled “Create a knowledge mining solution with Azure AI Search”Use case: You have lots of information and need to find information in it and analysis of it.
Azure AI Search combines AI search on your data and includes insights. As a service, it can index information, then do media analysis (image, PDF, hand writing, documents).
-
Indexers, indexes, and skills
The core of the Azure AI Search solution is an indexer which has a repeatable process to:
- Ingest data from a source, like documents or database
- Crack (scan) documents to extract their contents - for example, retrieving the text and image data in a PDF
- Do sequence of tasks to get information from the data and generate
a hierarchy of fields for the index
- Some fields are core attributes of the source data like document
file names and last saved dates. Others fields are generated by
using AI skills like:
- Using Azure AI Vision services to generate tags and captions for images.
- Using Azure AI Language services to derive fields for sentiment or named entities.
- Using Azure AI Document Intelligence to extract field values from forms.
- Some fields are core attributes of the source data like document
file names and last saved dates. Others fields are generated by
using AI skills like:
- Store extracted fields as an index like a text and vector hybrid store
The resulting index can be used to enable users to search for information in the extracted fields based on keywords and filters.
-
Persisting extracted data to a knowledge store
Azure AI Search can persist (store) extracted data to a knowledge store in Azure storage. The indexer saves these kinds of information in the store:
- Tables of field values
- Images extracted from documents
- JSON documents representing data structures, they can be hierarchies of fields and values