
This document describes the system design for the project.
Because of the request from the client, an effort is made on explicitly stating alternative solutions that we could have adopted and the reason why we decided not to adopt them.
This document is organized in the following way. First, we describe the overall system architecture in terms of data flow and how components interact with each other. Next, we visit three main sub-systems of the system separately and specify the interfaces between them and between the components inside each sub-system. Finally, we move on to each component that makes up those sub-systems, and specify the design of them. Some details which are useful only to implementors are explained in appendices.
The following figure illustrates the overall structure of the system. The file icons represent data stored as files, boxes represent sub-systems.
The system consists of three loosly coupled sub-systems:
From the functionality perspective, the system will provide the following services.

The actor is the user from the internet. There are three use cases for the user:
The "Place Order" use case uses three other use cases:
There are two dependencies between use cases.


This is a high level view of the interactions between the user, OrderFulfillmentEngine and getPDF CGI.
This sub-system is triggered by a batch script upon an update in the original US Code (such an update happens typically once a month). Each component in this sub-system runs against one title of the Code.
The first component "txt2xml" transforms a Code ASCII file (which corresponds to one title) into a "title XML" file, which contains the whole contents of one title of the US Code in one XML file. Both the input and output are files. This component is a perl script originally written by the previous CS501 team, and as stated in the requirement document, this design will not attempt to modify this component.
The "xmlSplitter" component splits a title XML into a set of "division XML"s. A division XML is an XML that contains one Code division. This component will receive the file name of the source XML file and the directory in which XML chunks will be produced. See the appendix for the naming convention of division XMLs. This component will be also written in XSLT. Refer to the appendix for the specification of the format of the division XML.
The third component "xml2html" transforms division XML files (which was produced by txt2xml) into a series of HTML files. The input to this component is the number of the title. This program then generates HTML files for all divisions inside the specified title and places all of them into the target directory. This component is written in XSLT by the previous CS501 team. To implement the new functionalities in the web site, this design requires the modification to this existing XSLT stylesheet, as well as the "driver" program that wraps the whole transformation processes as an executable program. Names of the generated HTML files follow the naming convention described in the appendix, plus a slight exntension to support things like notes. This naming convention is also developed by the previous CS501 team, but never been documented.
The "xml2pdf" component transforms division XML files (which was produced by xmlSplitter) into a series of PDF files. The input to this component is (1) the number of Code title to process, (2) the file name of the generated PDG catalog file. The component will produce PDF files and place them into the directory specified in the configuration file, and it will also produce a product catalog for the PDG shopping cart, which describes the price of each generated PDF. See appendix for the format of this file.
Obsolete. We need a different deployment strategy. The "PDG import tool" is a component that reads a CSV file, which is the output of the xml2pdf component and turns it into the native format of PDG shopping cart and places it into the directory where PDG shopping cart is deployed. This program is developed by PDGSoft and provided as a supplementary tool of PDG shopping cart package. The source code is not available.
All of the components in this sub-system are the console-based program, and their status messages (such as errors/warnings) shall be sent to the console in a human-readable format (they are not neccessarily in a machine-readable format). All except the "txt2xml" component takes a configuration file as a parameter, from which various environmental information is read. See the appendix for the format of this configuration file.
The client has developed and deployed an automated batch shell script which invokes "txt2xml" and "xml2html" in a sequence. The system shall extend this batch script so that other new components described in this section will be also executed.
This design does not specify any other program that coordinates these programs.
There is a document written by the previous CS501 team that describes the structure of the initial Code XML file. This file is available at http://leda.law.cornell.edu/~LDMS/docs/DTD%20Design%20Document-2000-11-28.doc, but unfortunately this document doesn't seem to reflect the changes made to the format after the first phase of the development.
A DTD, which formally describes the format of the XML, is also available at the project CVS repository, but this too doesn't seem to reflect the changes.
In this project, as stated in the requirements document, we will not modify the structure/format of the title XML, and we will develop new stylesheets by following the structure of existing XSLT stylesheets to make up our lack of knowledge about the structure of this XML.
To allow users to shop PDF files, we will modify and add new contents to the existing US Code web site (www4.law.cornell.edu/uscode). This section describes what changes we will make.
The user will browse HTML versions of US Code just like he does right now, or click on the newly added PDF icon on the right hand side of each division to add corresponding PDF file to his shopping cart (see selection-UI-1).
If an user clicks the PDF icon, the selected PDF shall be added to the cart and he shall be navigated to the confirmation page, which will be described in the step 2. To implement this semantics, the PDF icon shall be linked to https://www.law.cornell.edu/cgi-bin/shopper.cgi?add=action&key;=[SKU], where [SKU] is the SKU of the PDF file (see the appendix for the detail of SKU.)
From any US Code web page, such as selectino-UI-1 or selection-UI-2, he can click the "View my cart" link on the right hand side of the web page to view the current items in his shopping cart. To implement this semantics, the web page shall navigate users to http://www.law.cornell.edu/cgi-bin/shopper.cgi?display=action.


By clicking a PDF icon or by clicking the "view my cart" link on a page, the user will see the page shown in the figure contents-UI-1. This page allows him to perform several operations:
This page shows various information about the cart, such as quantities, descriptions of PDFs he has, prices, and total price.
add=action in the above URL to preadd=action we can add the confirmation page. This page would let the user to change his mind before the PDF file is actually added to the shopping cart.By navigating him to this page, the shopping cart will display the following screen. The "shop some more" buttton is linked to the web page that he was visiting before he clicks the PDF icon.

By clicking one of two check-out buttons in the contents-UI-1 page, the user can start the check out process. The user will then prompted to fill in information such as credit card number, name, and so on.
Once an order is placed, the user will see a "thank you" page, and the shopping cart system sends a notification e-mail. This e-mail is sent to the internal mailing list, which will be picked up later by the order fulfillment sub-system for processing. For the detailed web site structure, see the site map.
Those pages are rendered by the PDG shopping cart system, and we will just follow the configuration of the currently deployed system for the consistency; we are not going to modify it anyway.
The following site-map shows the navigation structure of the new web pages.

For every newly placed order, PDG shopping cart will send an e-mail, which is intended to notify shop managers. The format of this e-mail is described in the appendix.
PDG shopping cart shall be configured to send this notification e-mail to a mailing list which will be set up inside LII. This mailing list will send this e-mail to both the shop manager (for records) and a mail box which is dedicated for the order fulfillment engine. E-mails are spooled in that mail box by the mail server and wait for processing. In other words, this mail box serves as a queue for unprocessed orders.
The order fulfillment engine will be executed periodically (by cron daemon and/or by manually invoking the program if it is necessary). The engine accesses this mail box by POP3 and process those e-mails one by one. A processing of an order starts by parsing an e-mail, then dispatches a delivery e-mail to the user, and ends with the deletion of the e-mail from the inbox.
In case of any failure during the processing of an order, the engine must forward the original e-mail with error message to the administrator. The administrator is responsible to solve the problem and re-submit the failed order into the engine (s/he can do so by simply forwarding an e-mail back to the engine again.)
The engine shall produce a log of each processing and send it to a log file.
The engine shall generate one e-mail with a HTML attachment and send it to the customer who have placed the order. HTML attachment shall contain the following items:
Note that in many widely deployed browsers such as IE and NN, typing an URL of PDF files results in opening that PDF file within a browser window, which makes it very difficult for users to actually download those files. Therefore the instruction in the HTML attachment shall instruct the user to right click the link and select "save link as" menu.
For those mail programs which do not support HTML e-mail, the plain text part of the e-mail shall instruct the user to save the attached HTML file into disk and open it with a browser.
The entire e-mail shall be sent with the "multipart/alternative" MIME type so that the text part will be ignored with HTML-aware mail readers. Refer to RFC1341 (http://www.w3.org/Protocols/rfc1341/7_2_Multipart.html) for details.
HTML part of the e-mail shall look like this:
To satisfy the requirement that a knowledge of one PDF file location shall not let the user infer locations of other files, the system will "scramble" the hyper link to PDF files. This section describes how the URL is scrambled.
A link to a PDF file shall be in the following form:
http://.../..../GetPDF.cgi/XXXX.pdf?OrderID=OOOOO&Code=YYYYYYY, where "XXXX","OOOOO", and "YYYYYYY" are all alpha-numeric strings of variable lengths.
"OOOOO" part is the order ID, which was assigned by PDG shopping cart. This ID is included in the URL to make it clear to users that we are monitoring what they will do with this URL. It is expected that this serves as a mental brake to casually distribute PDF URLs illegally. Also, having order ID in clear part would make it easy to find any abused URLs from Apache log files by using existing log analysis tools for Apache.
"XXXX.pdf" is the non-scrambled name of the PDF file. By having the non-scrambled name in this way, most of the browsers will use this file name as the default file name when they prompt a dialog box to the user. "XXXX.pdf" shall follow the standard naming convention of the files. Note that this naming convention does not contain the title number.
"YYYY" part will be generated by first encrypting the following message by DES and then encoding the obtained ciphertext into ASCII characters by MIME BASE64 encoding.
The format of the un-encrpyted message is OOOOO,AA,XXXX where OOOOO is the order ID that produced this URL. AA is the title number and XXXX is the name of the PDF file without extension. Note that all the fields could be of variable length. To make sure that the URL is not tampered, related programs must make sure that information in the clear text part and the scrambled part agrees each other.
To ease the deployment process, the key used to encrypt/decrypt the message shall be hard-coded into the program. However, it shall be easy for a later development to modify this behavior (such as loading a key from an external file.)
The GetPDF component will deliver the actual PDF data to the user. This program will work as a CGI program and waits for the user request. Once the user connects to this CGI, it decrypts the PDF file path information from the URL, locates the PDF file, then sends the bytes back to the user.
http://lula.law.cornell.edu/cgi-bin/pdf/GetPDF.cgi/12/1026.pdf?XXXXX, and it lets the GetPDF CGI process this request.
Due to the lack of good DES implementation in Perl and perl experience of the team, this program shall be developed in Java, with a tiny bootstrap shell script called "GetPDF.cgi" which will start the Java program.
This component shall set the MIME type of the returned stream to "application/pdf", the registered MIME type for PDF files. We shall not make any effort to set the MIME type to other types just to force browsers open a download dialog box (we will rely solely on the HTML attachment of the e-mail to provide an opportunity to download PDFs.)
The basic logging functionality for CGI programs are provided by Apache, and no logging functionality that goes beyond this will be implemented.
This section sets forth the design of each component of the system in detail.
Component-wise, the system looks like following:

File icons represent data stored as files, boxes represent components that are implemented as executable programs. Columns represent data stored in formats unknown to us.
This component has the following command line syntax:
LDMS.pl <ASCII file name> -o <output file name>
Note that there is a known problem in this component that prevents us from specifying arbitrary file name as the output file name. So any program that uses this component had better use output redirection.
xmlSplitter <title XML file> <output dir>
Implementors are encouraged to provide additional command line options.
This component shall be implemented either as a Java program invoking XSLT transformation.
xml2html <title number> -c <config file>
Implementors are encouraged to provide additional command line options.
This component shall be implemented as a Java program, which uses XSLT transformation for actual transformation to HTML file. This component shall reuse the existing XSLT stylesheet.
This component is just a set of classes which is used by other components. Since it's not used as a stand-alone program, there is no command line syntax.
The following classes are shared by other components to model the basic concepts of the Code.

The CodeTitle class and the CodeDivision class are used to represent abstract concepts of "title" and "division" of US Code.
The primary role of these classes are to hide the physical layout of the resources (such as XML file or PDF file) from the rest of the system. Methods like the readPDF method or the parseXML method allow the other components to access those resources without knowing the actual location in the file system.
Another role of these classes is to provide a virtual hierachy of code divisions which can be traversed. The entire code consists of a set of titles, and a code title consists of a tree of code divisions. The navigation functionality over this virtual tree is exposed to the other components (through methods like the enumChildren method and the getParent method). In particular, the enumeration mechanism lets other components enumerate divisions through a callback interface called DivisionHandler.
The code division class also expose several simple methods which can be used to obtain information about the division, such as the level of a division (e.g., is it a chapter or a section?), the display name of a division (e.g., "ACTS AND RESOLUTIONS; FORMALITIES OF ENACTMENT; REPEALS; SEALING OF INSTRUMENTS").
The Order class represents an order. An order consists of a set of OrderItemInfo, each holds information about one PDF file which was ordered. The OrderItemInfo class provides two operations (fromURL/toURL) which implements the scrambling and de-scrambling of URL. Also, OrderItemInfo object is usable by itself without the parent Order object.

The Logger interface provides a logging service to the rest of the system. It exposes a set of methods to write a log file. Using an interface instead of a concrete implementation allows us to change the destination of log messages without affecting the other part of the system.
The FileLogger class shall be also implemented, which will send log messages to a file. The path of the log file should be configurable.
xml2pdf <title number> <catalog file> -c <config file>
Options and parameters can be interleaved (thus "-c <config> <title> <catalog> is a valid command line). Implementors are encouraged to provide additional command line options.
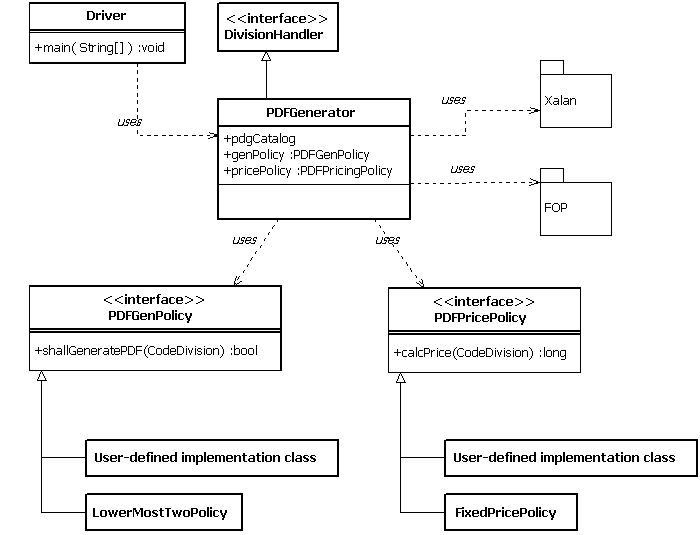
PDF generation is done in per-division basis. Therefore, the PDFGenerator class, which is the main class that generates PDF files and a catalog file for PDG shopping cart, is implemented as a DivisionHandler. An external driver class can start the PDF generation process by passing an instance of PDFGenerator to one of the enumeration methods of the CodeDivision or CodeTitle class.
PDFGenerator uses two policies that controls the generation process. One is the PDFGenerationPolicy interface, and this policy controls whether a PDF file should be generated for a given Code division. The other is the PDFPricingPolicy interface, and this policy computes price for each generated PDF file. PDFGenerator receives these policies as parameters of the constructor, and this class shall be completely independent from any particular implementation of those policies.
To allow policies to be changed without recompiling the program, the Driver class will consult the global configuration for the names of the policy implementation classes. Initially, we will role out one implementation for PDFGenerationPolicy, which generates PDF files for divisions in lower most two level. We will also implement one PDFPricingPolicy which sets the price of all PDFs to $1. The plan is to revisit the pricing policy after the system starts working.
The actual PDF generation shall be done by first using XSLT to transform a source XML into XSL/FO, then by using FOP to transform XSL/FO into PDF.
PDFGenerator also produces a catalog file for PDG shopping cart. See the appendix for the format of this catalog file.
Any error message during the processing shall be sent to the standard error, instead of a logger.
ofe -c <config file>
Implementors are encouraged to provide additional command line options.

The core part of the order fulfillment component follows the pipeline architecture. A pipeline consists of three interfaces. It starts with OrderReader, followed by zero or more OrderFilter, then finally ends with OrderHandler.
We will role out three components.
The first is the OrderEmailReader class. This class implements OrderReader. It reads order confirmation e-mails from the mailbox, parses it, constructs an Order object, then finally passes it down to the next component in the pipeline.
The second pipeline component is the OrderLogger class. This component uses Logger and record the time when it starts processing and the outcome of the processing.
The third pipeline component is the OrderSender class. This component generates HTML e-mail and delivers it to the user. Construction of HTML e-mail and SMTP protocol handling is done by a separate utility class named HTMLMailSender.
All the configuration (such as the name of the mail server and the mailbox name) shall be obtained through the system property.

The program starts with the Driver class, which contains the main method. The Driver class first sets up a pipe line, which is not depicted in the above figure. Then, the processing goes as follows:
getpdf -c <config file> <PATH_INFO env var> <QUERY_STRING env var>
A CGI program cannot take any command line arguments. Therefore, a wrapper shell script that just passes those arguments to the Java program shall be developed. Implementors are encouraged to provide additional command line options.
The GetPDF component does not involve any additional class other than the classes described in the shared component part.
The program shall take PATH_INFO and QUERY_STRING CGI variables as command line parameters. Checking correctness of a given URL and obtaining actual PDF byte stream are both done by the shared component.

An user clicks a hyperlink inside the HTML e-mail. This causes a browser to send an HTTP request to the GetPDF CGI program at lula [1]. The CGI de-scrambles the specified URL by using the fromURL method of the OrderItemInfo class [2]. Any malformed URL is detected by this method.
If the URL is correct, an OrderItemInfo object is returned, which contains information about the PDF file to be retrieved [3]. The CGI then uses the readPDF method to retrieve the image of the PDF file [4,5,6] and send it back to the browser [7].

The envisioned envrionment that this system will be deployed consists of three computers connected to a network. The abovementioned components shall be deployed as follows:
Describe things that we need to keep in our mind. Such as the shopping cart problem, deployment, cronjob, and so on.
The whole system can assume that it will be run on lula. Due to the size of the US Code, a special care has to be taken to the memory consumption during the processing. Note that lula comes with 2GB of memory.
The mail box for the order fulfillment engine should be set up so that it won't accept any e-mail from outside. For otherwise, it is possible for a malicious user to send a fake order notification e-mail to the system and have it deliver whatever PDF files s/he wants without paying fee.
As a result of an update to the ASCII version of the Code, divisions can removed. The currently deployed script for automated update just removes all the old contents and replace them with freshly generated contents. This means that customers that have ordered PDF files that correspond to the removed divisions will not be able to get their PDFs.
The system will not provide any particular support for those customers.
Division XMLs can be obtained by splitting a title XML as follows:
For example, given the following source title XML:
<STRUCTDIV>
.... 1 ....
<STRUCTDIV>
.... 2 ....
<STRUCTDIV>
.... 3 ....
</STRUCTDIV>
.... 4 ....
<STRUCTDIV>
.... 5 ....
</STRUCTDIV>
.... 6 ....
</STRUCTDIV>
.... 7 ....
</STRUCTDIV>
According to the above rules, we will obtain the following four division XMLs.
a.xml ----- <STRUCTDIV SELF="a"> .... 1 .... <STRUCTDIVREF REF="b" /> .... 7 .... </STRUCTDIV> b.xml ----- <STRUCTDIV SELF="b" PARENT="a"> .... 2 .... <STRUCTDIVREF REF="c" /> .... 4 .... <STRUCTDIVREF REF="d" /> .... 6 .... </STRUCTDIV> c.xml ----- <STRUCTDIV SELF="c" PARENT="b"> .... 3 .... </STRUCTDIV> d.xml ----- <STRUCTDIV SELF="d" PARENT="b"> .... 5 .... </STRUCTDIV>
The SELF attribute holds the name of the division itself, whereas the PARENT attribute holds the name of the parent division. If there is no parent (that is, the division is the root division), the PARENT attribute is not present.
A STRUCTDIVREF element is placed where a STRUCTDIV was in the title XML. This element has the REF attribute, which holds the name of the child division.
The Order Fulfillment Engine (OFE) will retrieve the order information from this mail. The format is as follows:
To: OFE@lula.law.cornell.edu
Subject: Order Placed--[ORDER_ID]
Order [ORDER_ID]
For [CUSTOMER_NAME]:
Qty Description Unit Amount
--------------------------------------------------------------------------------
1.00 TITLE 26 Subtitle A CHAPTER 1
Subchapter B PART II Sec. 75.
Sec. 76. PDF[26=CH1_SEC7576] $5.00 $5.00
--------------------------------------------------------------------------------
Total Shipment Weight: 2.00 lbs. Subtotal: $5.00
Shipping & Handling: $0.00
Total: $5.00
Total Frequent Buyer Points: 5.00
Order placed at: Wed Mar 06 18:27:39 2002
-
SHIP TO:
Charles Chiu
123 First Av.
Ithaca, NY 14850
United States
Shipping Method: Standard Shipping
E-mail: charles@hotmail.com
Remote IP Address: 127.0.0.1
BILL TO:
Charles Chiu
123 First Av.
Ithaca, NY 14850
United States
Phone 1: 1234567
Payment Information: Off Line Credit Card
Format of product description: DESCRIPTION + SPACE + "PDF[" + TITLE# + "=" + DivisionName + "]"
Descriptions of products shall include the name of the PDF file at its end, and OFE shall parse this part to retrieve PDFs that have ordered. Note that, as in the example, a description can be wrapped into next line.
The PDF generator component will produce a product catalog file for PDG shopping cart in the following format:
;PDG Shopping Cart Product Definitions
;
;Auto-generated by PDG Data Importer
;Do not modify manually unless you know what you are doing!
;
Begin Product {SKU}
{Description}
{Price}:0.00 0.00
0.00 0.00
No ; Tracking Inventory?
End Product
;
Begin Product XY2sJ5
TITLE 26 Subtitle A PDF[26=stA]
1.00:0.00 0.00
0.00 0.00
No ; Tracking Inventory?
End Product
;
continue ...
For one product, 9 lines (from Begin ... to ;) are required. This 9 lines block are repated for all products. The part shown in italic and red should be replaced by appropriate strings (see the XY2sJ5 item for the example.)
TITLE 26 Subtitle A CHAPTER 1 Subchapter B PART II Sec. 77. PDF[26=stAch1scBpII]"
In the PDG shoping cart, a set of products can be put together into a "category". Each product category will have its own product database file. Because of the restriction of the PDG shopping cart, a category can't have more than 20,000 products.
For performance reason, a category shall be create for each Code title.
The previous CS501 team introduced a naming convention that is supposed to uniquely identify any division of the Code in one title (note that two divisions in two different titles can have the same name). This naming convention is used as file names for most of per-division resources such as HTML and PDF.
The following algorithm computes the name for a division:
let r be the STRUCTDIV element of which we want to compute the name.
let ref be the result of executing XPath query of
"TITLEDATA/NAVGROUP/HEAD/@REF"
let parentRef be the result of executing XPath query of
"TITLEDATA/NAVGROUP/EXPCITE/@REF"
if ref starts with either "p","sp","ch","sch", or "d" then
if parentRef contains ref as a substring then
use parentRef as the name
else
use parentRef+ref as the name
end if
else
use ref as the name
end if
Each PDF file needs to have an unique SKU which is used by the PDG shopping cart to identify it as a product. Because of the constraint imposed by the PDG shopping cart, we cannot use SKU longer than 20 characeters, which makes it impossible to use file names directly as SKU.
Given a title number tn and file name name, the SKU shall be generated as follows:
According to the restriction of PDG shopping cart, the first four characters must be the product category name. tn in the fourth character is escaped to printable ascii character. The PDG shopping cart system is also used by other systems of LII, therefore this four character prefix is also necessary to avoid name conflicts with other currently deployed systems.
The "BASE64'{ ... }" part denotes the MIME base64 encoding (see RFC 2045) of the "..." part, followed by replacing '+' by '-' and '/' by '_'. In this encoding, we will encode the title number tn as one byte, followed by Adler-32 check sum of name as four bytes (in little endian), further followed by CRC-32 check sum of name as four bytes (also in little endian). Encoding 9 bytes in BASE64 yields 12 characters. Finally, the first 4 characters of the file name is appended (if name is shorter than 4 characters, the whole string is appended).
Generated SKUs will be always at most 20 characters.
The system depends on various environmental settings, such as the name of e-mail server. These configurations are supplied to the system in Java property file format (http://java.sun.com/j2se/1.3/docs/api/java/util/Properties.html#load(java.io.InputStream)).
The following table specifies the name of properties and their purposes.
| Property Name | Function |
| Example | |
| LIIPDF.common.path.xml | Path name of the directory where division XML files are stored. A sub-directory will be created for each title under this directory, and actual division XML files are stored inside that directory. The path name must ends with the path separator '/'. |
| /usr/local/uscode/xml/ | |
| LIIPDF.common.path.html | Path name of the directory where HTML files are stored. The same rule and constraint applies as the "LIIPDF.common.path.xml" property. Different path parameters can have the same path name (in that case different file formats are stored in the same directory.) |
| /usr/local/uscode/html/ | |
| LIIPDF.common.path.pdf | Path name of the directory where PDF files are stored. The same rule and constraint applies as the "LIIPDF.common.path.xml" property. |
| /usr/local/uscode/pdf/ | |
| LIIPDF.common.DESKey | This key will be used to scramble PDF URLs. It is a hexadecimal representation of 64-bit DES key. An administrator can always generate a fresh key by using a supplementary DESKeyGen tool or any other publicly available tool that can generate 64-bit DES key. |
| 04B915BA43FEB5B6 | |
| LIIPDF.ofe.pop3serer | Order confirmation e-mails from PDG shopping cart will be retrieved from this POP3 server. |
| donut.cs.cornell.edu | |
| LIIPDF.ofe.pop3user, LIIPDF.ofe.pop3password | The POP3 account name and the password that will be presented to the POP3 server to access e-mails. Passwords are written in a clear text. |
| pdfOfe,password | |
| LIIPDF.ofe.smtpServer | Name of the SMTP server which will be used to send e-mails to customers. |
| smtp.mail.yahoo.com | |
| LIIPDF.ofe.supportEMail | This e-mail address is used as the sender of the order delivery e-mail. Therefore, when a customer hits a reply botton, it will be sent to this address. So we expect this e-mail address to reach a tech support personnel. |
| pdf.tech.support@law.cornell.edu | |
| LIIPDF.util.logger | Fully qualified name of the Java class that implements the Logger interface. This class will be used to write log messages. We don't expect a system administrator to casually modify this parameter. |
| edu.cornell.law.liipdf.util.FileLogger | |
| LIIPDF.util.FileLogger.logfile | Used by FileLogger, the default logger. This property specifies the full path name of the log file to which log messages are sent. |
| /usr/local/uscode/logfile.log |