Scalability of Webcrawlers designed in SML (Standard Meta Language)
By Jeff Chiang and Justin Tung
Storage of Data
To start to consider scalable webcrawlers involving arbitrarily large data,
the abstract data types to be looked at should be ones that involve low
worst case run times in functions such as lookup and insert. Looking at the
data structures learned so far, red-black balanced trees provide the optimal
big-O running times for lookup and insert which are both O(log n). The
advantage O(log n) running times for these key functions becomes apparent
when n reaches billions as is the case when an indexer is storing and wading
through all the data on webpages. New webpages are easily inserted into the
existing scheme and old ones can be found easily and updated. A possible
implementation might be to count the length of the URL and store data based
on that number. Another way could be to sort data into subtrees based on
certain other ways of dividing the information on the web (i.e. file extensions
of URLs, general topics). can be done via a record which stores fields that
contain specific information about page title, language, format (from URLs and
potential file links) as well as information about the content on the page.
This content like the index of webpages should be stored in the same format
to provide optimal lookup times for words, phrases, etc.
Content and page title are probably the most important elements in a search in the web and should be displayed along with the URL in a results page. However, advanced searches going beyond simple boolean expressions requires more complex analysis of data in the fields. Current search engines support phrase finding, negative queries, language specific queries, and similar pages or pages that link to a certain page. Additional support includes searching certain directories (images, newsgroups, audio/mp3s, downloads, etc.), dated page queries, and even reviewing most recent queries (probably to save resources by bringing up information already searched for previously).
How to implement these 'advanced searches'?
Using the data structure setup discussed above, advanced searches really
are based on good algorithms that go through the data stored in an index
and pulls out the important information. Phrase finding wil l require the
ability of the search engine to parse text into groups of words and compare
them, once a page meets this phrase requirement, the URL and its corresponding
information should be sent back. Negative queries work similar to 'positive'
queries and it should be a negation of the implementation used for regular
queries. Similar pages can be searched for by keywords in page titles, text,
and other data stored on the page. Finding links to a certain page should be
easy using the tree setup since a find on all URLs that have a common link
can be done and the URLs returned. Subtopics and more specific areas of the
web can be implemented by dividing data during the insert into the web index
as mentioned above with subtrees. Then searches will be limited to those
trees when needed, thus decreasing running times by limiting what topics/data
to search for. The implementation of storing recent or most popular queries
can be done by storing a set of URLs in a database (balanced tree) either
for reference or for near future use. This storing of returns on queries
helps cut down the amount of queries (in which many could be the same) to
a search engine.
Analysis of Running Times and Scalability
considerations to Web Search Algorithms
Since all the webpages are stored as balanced trees and within those
trees, the nodes store content data in balanced trees, search for a specific
page (i.e. URL) could be done in O(log n) time. The good thing about balanced
trees within balanced trees is that any other type of search that might access
fields in the nodes will take at most O(log n) time. Since data on the
internet is so large, worst-case running times do provide a good estimation
as smaller orders such as constants (accessing data) do not really affect
running time. As a result of processing terabytes of data, frequency of crawls,
and the general expectations of speed on the internet, algorithms with the
smallest possible big-O are the most desirable. Fast algorithms will be able
to service the large amount of people using the search engine everyday in good
time.
Caching Web Pages
Although the caching of every examined page may seem like an impossible task,
it is indeed what Google does. Google employs a compression technique on
each document that trades off speed for file size. Its 3:1 compression ratio
allows moderate space-saving while still retaining adequate retrieval speed.
Each document is stored with a docID, length, and URL. In addition to this
central repository, a document index, lexicon, hit list, and hit list indexes
are stored as well. The document index stores in each entry the current document
status, a pointer into the repository, a document checksum, and various statistics.
The hit list corresponds to a list of occurrences of a particular word in a
particular document including position, font, and capitalization information.
All of this information is then used to create the hit list indexes,
which record the docID of a document that contains the words in the hit list.
Even the queries themselves are cached, resulting in faster search times
should the same query be repeated. The result of these data structures blended
together is a fast and accurate return of the pages requested by users.
Frequency of Web Crawls and Changing Web pages In order to keep track of
what pages have or have not changed, a record of the time of last access
of any page needs to be maintained. Any further attempt to access the same
page in less than the specified period of time is rejected and "local copy
up to date" condition is signaled. If a page has been accessed previously,
the HTTP HEAD access method is used to determine the last modified date of
the current remote version. If this is unchanged from the last modified date
of the current local copy then no further network traffic ensues and "local
copy up to date" condition is signaled. If the remote version has changed
then an HTTP GET access gets the new copy.
A search engine needs to maintain information about the last 10 accesses or attempted accesses to a resource. The stored information includes the date of access, time needed for transfer, amount of data transferred and the HTTP status code [right name]. In the internal database the status code is extended with non-standard to indicate various types of communication failure. If successive access attempts fail, the page is assumed to be no longer available. It is marked as such and may still be included in the database but is presented to the searching user with a warning. Eventually the page will be eliminated entirely from the database.
Water Conservation Presentation
By Justin Tung
Educate for the Earth 2000-2001: Presentation Sheet
Information taken from: http://www.epa.gov/ow/kids.html as well as various other net sources. Target audience is elementary school children and above.
Presentation
What is water?Water comes in 3 forms ice, water (the type that we usually see in oceans and lakes), and vapor (form of water in the air) - all have a clear color.
Where does it come from?
Water comes from sources on the Earth and is located in many places:
Some of these are: oceans, rivers, lakes, atmosphere, underground wells, and
glaciers in places like the Antarctica.
Our bodies are around 55-60 % water and the earth is 70% water.
We need water to live and stay healthy since a large percent of us is water.
Like us plants and animals also need water to survive. These include all living
things both on land and underwater and of course water is obviously important to
sea life like coral reefs, fish and sea plants.
It means to save and recycle our water so we use as least water possible.
"Water recycling is a critical element for managing our water resources.
Through water conservation and water recycling, we can meet environmental
needs and still have sustainable development and a viable economy."
-Felicia Marcus, Regional Administrator Water Division Region IX
Water recycling is reusing treated wastewater for beneficial purposes such as farming, business, and home processes as well as refilling a ground water supplies (water recharge). A common type of recycled water is water that has been reclaimed from city wastewater, or sewage.
Through the natural water cycle, the earth has recycled and reused water for millions of years. Water recycling, though, generally refers to projects that use technology to speed up these natural processes.
There are numerous water recycling projects to increase the quality of water that is recycled because the usual quality now is non-drinkable, but still useful for farming and industries.
By providing an additional source of water, water recycling can help us find ways to decrease water taken from sensitive ecosystems. Other benefits include decreasing wastewater discharges and reducing and preventing pollution. Recycled water can also be used to create or enhance wetlands and habitats.
In some cases, the reasons for water recycling comes not from a water supply need, but from a need to eliminate or decrease wastewater discharge to the ocean, an estuary, or a stream.
While water recycling is a sustainable approach and can be cost-effective in the long term, the treatment of wastewater for reuse and the installation of distribution systems can be initially expensive compared to such water supply alternatives as imported water or ground water.
As water demands and environmental needs grow, water recycling will play a greater role in our overall water supply. By working together to overcome problems, water recycling, along with water conservation, can help us to conserve and manage our vital water resources to last into the future.
Activities
What do you do already at home that conserves water?
Watershed - Adopt Your Watershed - http://www.epa.gov/adopt/
Encourages the saving and looking over of the nation's water resources.
Through this effort, Environmental Protection Agency challenges people in
the community to join them and others who are working to protect and restore
our valuable rivers, streams, wetlands, lakes, ground water, and estuaries.
What you can do at home
- At home you can significantly reduce the amount of wastewater from home systems and sewage treatment plants by conserving water - less water use means less waste
- You can try using low-flow taps, shower heads, reduced-flow toilet flushing equipment, and water saving appliances such as dish and clothes washers
- Repair leaking water sources in your house
- Avoid letting taps run unnecessarily like when people brush their teeth they leave the tap on
- Wash your car only when necessary; use a bucket to save water or go to a carwash that uses water efficiently and disposes of runoff properly - runoff is a source of waste and pollution
- Do not over-water your lawn or garden. Over-watering may increase leaching of fertilizers to ground water
- When your lawn or garden needs watering, use slow-watering techniques such as trickle irrigation or soaker hoses. (Such devices reduce runoff and are 20- percent more effective than sprinklers.)
Cleaning water process (figure 1):
- Coagulation - Coagulation removes dirt and other small things caught in the water. Chemicals are added to water to form tiny sticky balls that stick to the dirt and sink to the bottom of the water.
- Sedimentation - The heavy balls settle to the bottom and the clear water moves to filtration.
- Filtration - The water passes through filters, some made of layers of sand, gravel, and charcoal that help remove even smaller pieces of dirt and other things.
- Disinfection - A small amount of cleaning liquid is used to kill any bacteria or small living things that may be in the water.
- Storage - Water is stored in a large pool in order for dis-infection to take place. The water then flows through pipes to homes and businesses in the community.
What's wrong with this picture (figure 2):
- Stream erosion - the sides of the stream should be maintained - the sides are weak because people have stripped the sides of plant life which holds the soil together
- Oil dumping - leads to pollution of soil and ground water, also affects local wildlife
- Car leaking
- Over fertilization - can kill plants, harm the soil and create runoff pollution where fertilizers enter the water system
- Water waste - we want to conserve water and use a little as possible to keep our environment healthy
- Litter
How to Succeed in Technical/General Liberal Arts Courses
by Justin Tung
Introduction
I decided to write the text when I reflected on my most successful
courses grade-wise in university. I also found that these courses were the ones I
gained a large understanding and appreciation of the material and retained
much memory of what was taught in the course. I found I studied for them
all in a similar format and there was a general study method I used
unconsciously. I should also add that these particular courses were taught
by excellent professors and teaching assistants and often had good supportive
reading material.
The following text assumes a kind of lecture-recitation (section) class structure which is sometimes not the case if different types of classes (like labs, discussion sessions, etc.) are available. Also, some of the points (maybe all of them) sound quite common sensical or obvious to most students, but the difficult part is to attain the DISCIPLINE required to carry everything out to the end (i.e. go to all your classes, even the boring ones). If you attain this skill, you will be guaranteed a sense of accomplishment and learning and the rewards may be unlimited. In hindsight, this so-called discipline is much easier to obtain when:
- You like the subject/course content
- You enjoy the professor, TAs, teachers, etc.
- The presentation and learning styles suit you
- You chose the course because you like it
1. Lecture
- Read assignments for lecture no more than a week later so that the material is still fresh in your head. This method aids understanding of the material. The closer to lecture you read the material, the better your understanding and learning.
- Some classes even promote reading material to be covered in lecture before lecture. Be sure to at least attempt this since the course organizer sometimes presumes knowledge during the lecture which may be important for understanding.
2. Section
- Go over homework before a section and be prepared to ask questions if any. Do not forget to pay close attention to the questions of others, often these questions reflect common weaknesses in understanding of material.
- If you do not have the time to go over (or even take a peek) at the homework or it is not necessary to know it, make sure to take comprehensive notes.
- Make sure you have at least a slight idea of the material covered in sections and in some cases section should be a review and expanding on known material.
3. Essays/Projects/Problem Sets (Homeworks)
- If you have questions about homework go to office hours or ask the teacher.
- For projects and problem sets, you should look over the entire document the task at reviewing homework before it is done does not have to be a lengthy process and may only take a couple minutes.
- One of the problems with homeworks is knowing when to talk to a teacher. This timing should be determined by you. It difficult to analyze when the timing may be too early or too late, but being a little earlier always helps.
For essays, there are numerous methods on the internet about how to go about writing a good essay so I will not go into that except to say the general chronological order is: think about the problem/question, research, write a Thesis/Outline and organize arguments/data, set down which points go into which arguments, then write!.
4. Exams
- Review course material to be covered and LEARN it. I find it helpful to rewrite notes, key ideas, etc. or to write up "exam notes" which are easily to review in the few hours/minutes before the exam.
- Do questions/mock essays/practice exams
Conducting searches/research and data mining on the web
How to find information and resourcesThis section was originally part of my links area until I realized that it was important enough for its own section. The sites below helped me to find most my links and learn how to make and design webpages. Also, using the Internet has saved me countless hours in searching for and learning information. There is no real path to follow but I have listed the links below in order of importance to me.
One thing to keep in mind though when looking at information on the internet is do not trust or believe everything you read. A large amount of common internet (and urban legend) spread myths are available at www.snopes.com, which at least a couple you will have heard of, depending on your age and experiences. In the print world, most serious information sources go through screening, editors, publishers, and finally critics, while online information can be published by anybody, although if you get the information from a reliable website (e.g. a government one) you can rest a little more assured.
My process to find information online:
1) Usually I proceed to Google first and find the information right away. However, some information is found easier using other search engines (e.g. specialized ones) and Yahoo for example is best for finding financial and map information fast.
2) Of course finding the resources and search engines is half the effort, the other half is searching smart and knowing when to move on to other pages in the search, follow links on a page, or try another approach. Ideally, you should choose a search that narrows down the number of pages you have to look at to a manageable amount.
This process might involve adding more keywords, specifying advanced search conditions, looking at different resources, etc. At other times, simple is better (i.e. typing in virginia.com to find information about Virginia, USA) or just doing very general searches to find information quickly.
3) If you are having a hard time finding information because it is relatively specific try the meta search engines or try looking up sites in Google that pertain to your general subject area and continue the search within those sites.
4) In case the above steps fail, try accessing the resources below.
Google: One of the best search engines
with a fast and efficient searching algorithm.
About.com: Expert guides in many subjects
About.com like Yahoo contains information on many things except that the sites
are managed by experts in their field who give their input about a subject and
provide a set of links from which to explore. This site has easily moved
up my priority list in visiting when searching for topical information.
LYCOS: My second choice for a keyword
search engine, sometimes it finds sites Google does not and I guess as a
result uses a different page index and/or searching algorithm.
YAHOO!: Excellent array of resources,
contains just about everything (current events, finance, mail, maps, etc) and
has many services, it's different from some sites in that information on
Yahoo is sorted using library science methods.
usenet:
Newsgroups have been a source of interaction between varied internet users
and sometimes good short or long-term sources about information where a
personalized response or interaction is required. You might consider
looking into the 1000s of newsgroups for the topic that interests you or
ask people how to obtain information.
Other Resources
Guide
to Research using the Internet |
Encyclopedia Britannica |
Searchopolis
[Educational Searches] |
Raging Search
(AltaVista) | Merriam-Webster
Dictionary
ARTEMIS | resources/docstexts.html by justin tung generated using Apache Software Foundation's Xalan-J version 2.7.2

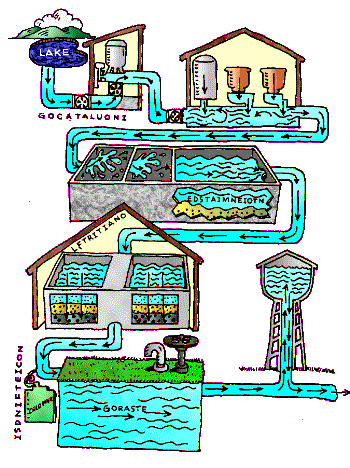{kind=link}
{kind=link}